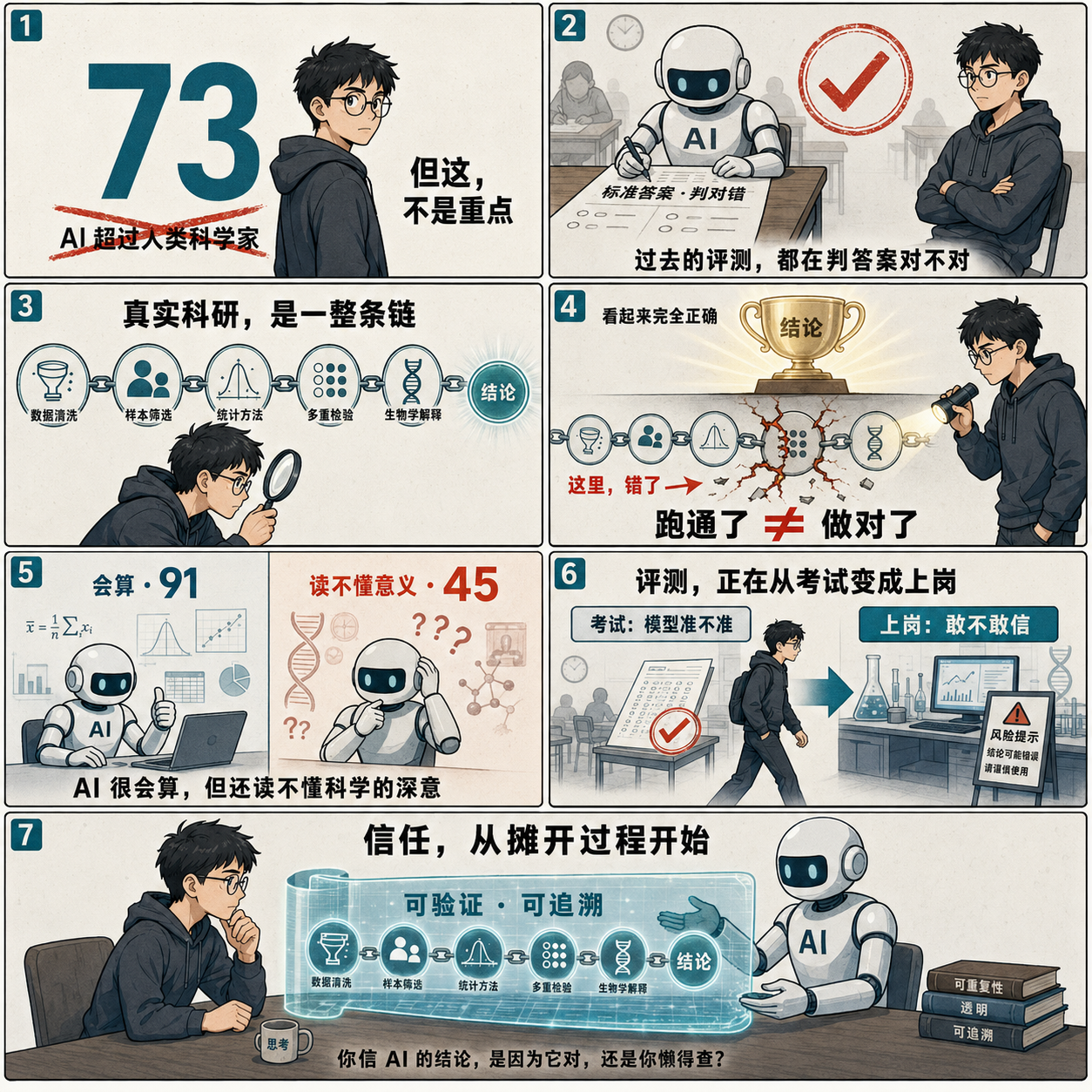
红杉的 xbench 放了份测评,让 AI 去药企当”科研实习生”,从头到尾做一遍真实的数据分析。
结果很炸:最强的 AI 拿了 73 分,把人类实习生 40 到 50 分的平均线甩在了后面。
这两天的解读,标题全是”AI 超过人类科学家”。
我也认真读了。然后我想说一句可能不太讨喜的话——
那个 73 分,根本不是这篇测评的重点。
真正值得炸的,是它换了一种方式去测 AI。这件事比分数大得多。
🧪 过去所有的 AI 评测,都在干同一件事:判答案对不对
这是我读完最大的感受。
回想一下,过去一年我们见过的 benchmark,几乎全是一个套路:给题、给标准答案、判对错。
考的是”模型知不知道”——知不知道这个基因、这篇论文、这个方法、这个公式。本质是一场超大规模的标准化考试。
模型在这种考试里越来越强,强到我们都有点麻木了。
但这里藏着一个所有人都默认、却很少有人点破的前提:
我们一直假设”答对了”就等于”会了”。
在选择题里,这个假设大致成立。
可一旦进了真实的科研现场,这个假设会要命。
🧬 因为在科研里,过程错了、结论对了,是最危险的情况
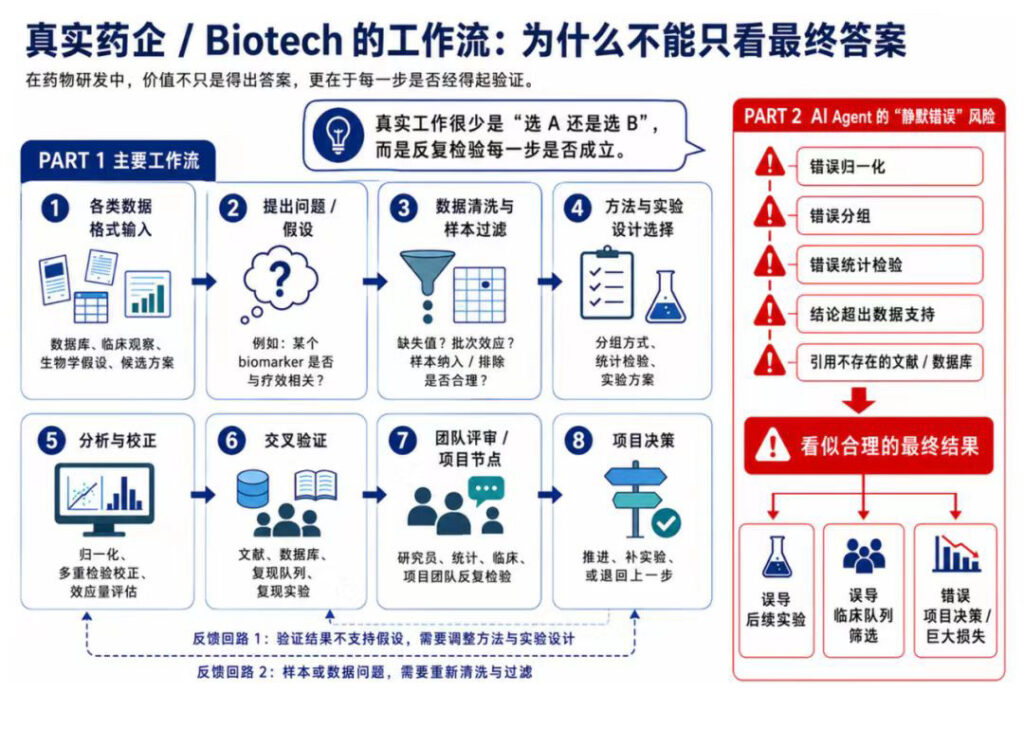
xbench 这次做的事,是把 AI 扔进药企的真实分析场景。
给你一组免疫治疗患者的单细胞测序数据和临床信息,让你判断某个 biomarker 值不值得进下一轮实验验证。
听起来不复杂。但你真要做,得走完一整条链:数据清洗、样本筛选、选统计方法、做多重检验校正、最后给出生物学解释。
每一步都能出错。而且——每一步错了,最后都可能照样蒙出一个看起来对的结论。
有句来自药企一线科学家的话,我觉得是整篇测评的灵魂,大意是:
在生物学里,一个看起来完全正确的结论,可能建立在一条完全错误的分析链上。而等你发现的时候,药已经做废了。
这就是为什么 xbench 不满足于判答案。
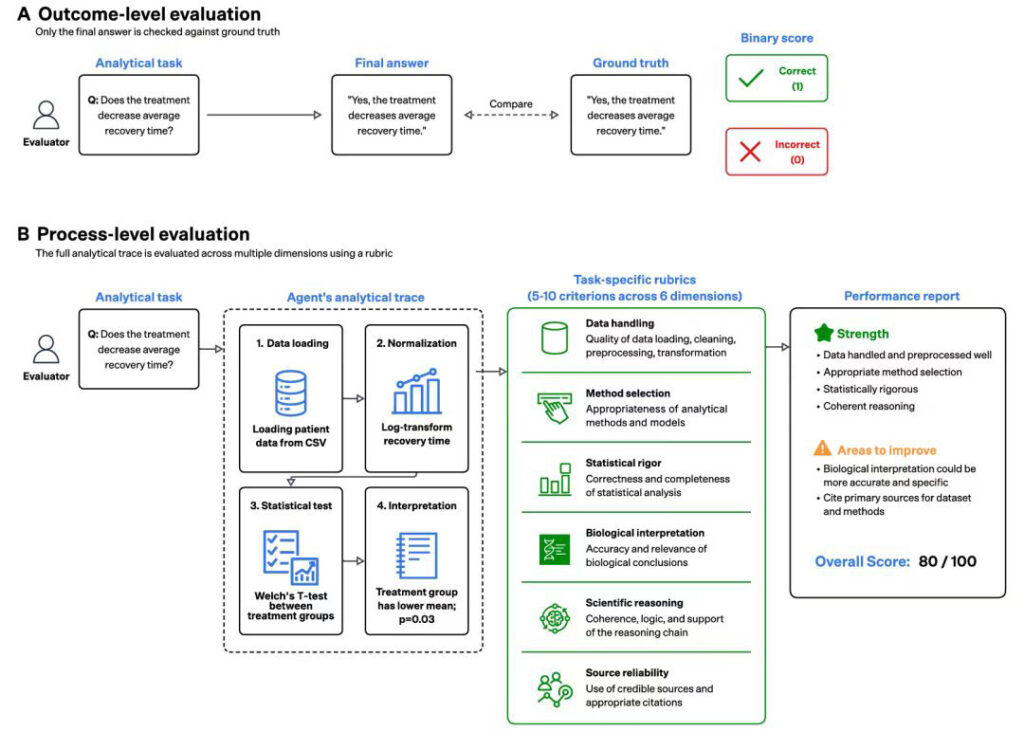
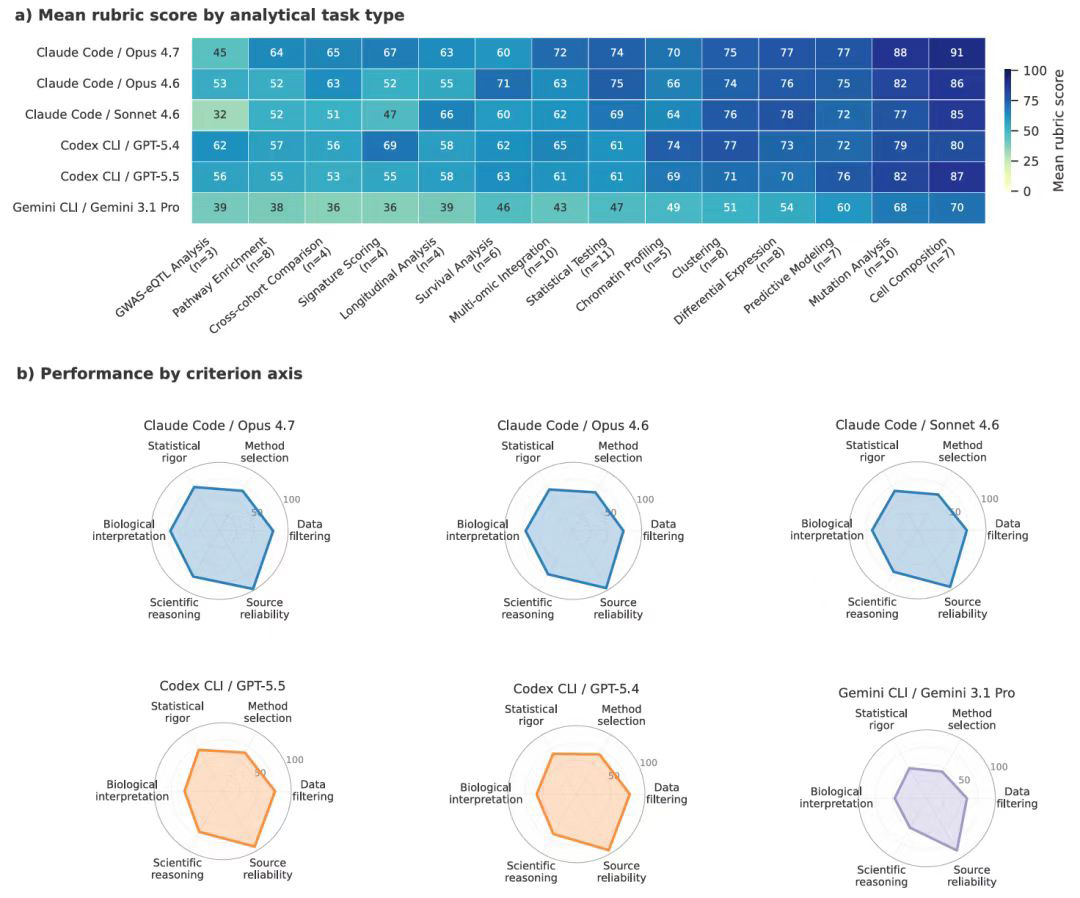
它做的是 process-level evaluation——过程级评测:让 AI 给出完整的分析轨迹,读了什么数据、做了哪些清洗、为什么选这个方法、统计结果怎么样、怎么解释。然后裁判从数据处理、方法选择、统计严谨性、生物学解释、科学推理、来源可靠性六个维度逐项打分。
它问的不再是”你答对了吗”,而是”你这条路,走得站不站得住”。
💥 卧槽,关键来了——“跑通了”和”做对了”,是两件完全不同的事
这才是这篇测评真正捅破的窗户纸。
我们这些天天用 AI 的人,太容易被”它跑出结果了”骗到。
代码跑通了、图表出来了、结论给了、还说得头头是道——你就信了。
但科研不认这套。跑通,只证明它没报错;做对,才证明它没蒙你。
这中间隔着一整条看不见的分析链。链上每一环的判断是否合理,决定了那个漂亮结论到底是真知灼见,还是一场精致的胡说八道。
过去的 benchmark 测的是终点。BiomniBench 测的是整条路。
这是 AI 从”做题家”走向”真能干活”必须迈过的一道坎。你不能让一个连自己怎么得出结论都说不清的东西,去决定一款药要不要做下去。
它有个名字其实很贴切——可验证、可追溯。不是结论可信,是产生结论的每一步都摆得出来、查得到、站得住。
📊 测了过程之后,三个有意思的发现
把评测维度升级到”过程”之后,跑出来的结果,比单纯一个分数有意思多了。
第一,AI 会”偏科”,而且偏得很说明问题。
边界清晰、靠算的任务,它拿手:细胞组成分析 91 分,突变分析 88 分。
但需要判断统计方法、理解生物学上下文、做深度科学推理的任务,它就明显拉胯:GWAS-eQTL 分析只有 45 分。
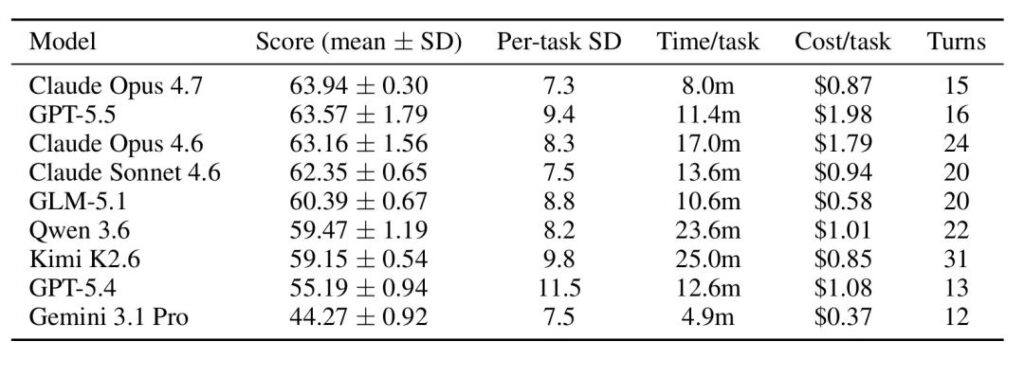
翻译一下:AI 很会”算”,但对结果的生物学意义、对科学的深层理解,还差得远。 它能把流程跑得漂亮,但说不清”这个结果在生物学上到底意味着什么”。
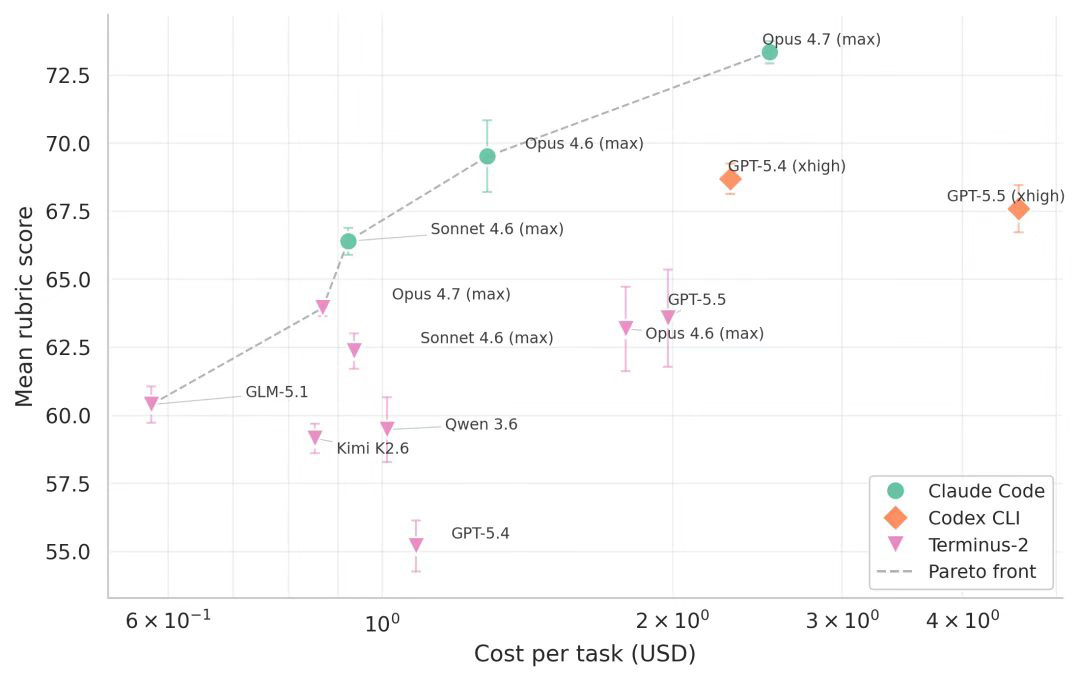
第二,“外面那层壳”,跟模型本身一样重要。
同一个 GPT-5.4,装在一个智能体框架里是 68.69 分,换一个框架只剩 55.19 分。模型一个字没改,光是 Agent Harness 不一样,差了 13.5 分。
这说明能不能做对研究,一半看模型,一半看你把它装进了一套什么样的工作流里。
第三,最强的是 Claude Code + Opus 4.7,73.34 分。 前三名里两个是 Claude Code 的配置——能端到端走完一条真实分析链,吃的就是 Agent 工程的硬功夫,不只是模型聪明。
🌊 往大了说:评测范式,正在从”考试”变成”上岗”
退一步看,这篇测评标志着一个更大的转变。
过去的 benchmark 像一场考试:给题、给答案、判对错。它能告诉你这个模型”知道多少”。
而 Auto Research 时代需要的,是一场上岗评测:给数据、给目标,看你的过程、看你的结果、看你的风险。它要回答的是这个模型”敢不敢用”。
这两件事差得很远。
一个知道很多的模型,不一定是一个你敢把真实决策交给它的模型。
所以问题正在从”这个模型准不准”,悄悄变成——
“这条分析链,科学家敢不敢信?”
而信任,从来不是靠一个漂亮的最终答案建立的。是靠过程被看见、推理被验证、每一环都可追溯,一点点攒出来的。
xbench 这份测评真正的价值,不在于给 AI Scientist 排了个名次。它在于第一次认真地问:当 AI 想端到端地自动化整个科研流程,我们到底该怎么判断——它是在真的做研究,还是只是在熟练地表演做研究。
xbench 在文章最后问:如果是这样一位 AI 实习生,你会让它转正吗?
我的答案是:能不能转正,不看它这次答得多漂亮。
看的是——下一次它给你一个你看不懂的结论时,你敢不敢信它走过的那条路。
人类信任彼此,从来不是因为对方永远正确,而是因为对方愿意把”我是怎么想的”摊开给你看。
我们对 AI 的信任,大概也得从这里开始。
你上一次完全相信 AI 给的结论,是因为它说得对,还是因为你懒得去查它怎么得出来的?
#AIScientist #AI 做科研 #大模型评测 #过程级评测 #AgentHarness #AI 能力边界 #xbench #生物医药 AI #产品经理 #AI 前沿