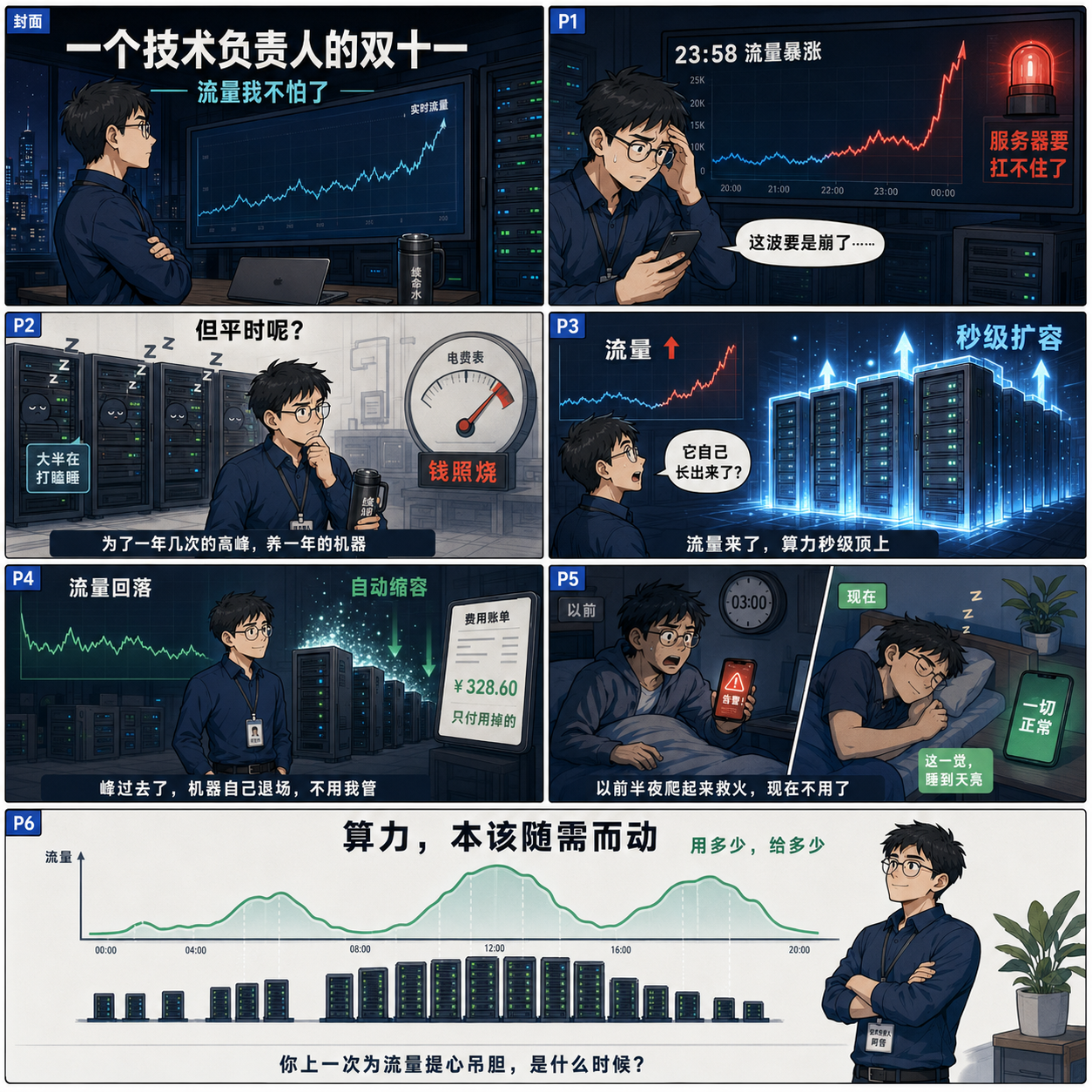
这是上面那套漫画的正文。漫画里阿哲的那一晚,我想很多带过团队的人都熟。下面把那晚背后的事,讲透一点。
做技术负责人的人,都有过阿哲那一晚。
大促前夜,监控大屏上那条流量曲线开始往上翘。你盯着它,手心冒汗,脑子里只有一个念头:这波别崩。
崩了,老板第一个找你;不崩,也没人记得你熬了通宵。
这是这个岗位最憋屈的地方——你做的所有准备,都是为了”什么都不发生”。
但真正让我睡不着的,其实不是大促那一晚。
是大促之后的 364 天。
🧮 真正烧钱的,不是高峰,是高峰和日常之间那道沟
阿哲漫画里第 2 页那张图,我觉得是整套里最扎心的。
一屋子服务器,大半在打瞌睡,电表却转得飞快。
这就是绝大多数团队真实的成本结构:你为了一年几次的流量高峰,买了一整年的机器。
算一笔账你就明白了。假设你的业务平时只需要 3 台机器,但大促那天峰值要 30 台。
传统做法是什么?为了那一天,你得常备接近峰值的容量——要么自建机房买 30 台,要么包年包月租 30 台。
结果就是:那多出来的 27 台,一年里有 360 天在空转。
它们没坏,没闲着报错,就是单纯地开着、亮着灯、烧着电、计着费,等那一年几次的高峰。
你不是在为”计算”付费,你是在为”以防万一”付费。而”以防万一”这四个字,是技术预算里最大的一个黑洞。
我见过太多团队,CTO 心里门儿清这笔钱浪费了,但不敢砍——砍了,万一哪天流量来了扛不住,谁担责?
于是这笔冤枉钱,年复一年地交。
⚡ 弹性部署在做的事:把”养机器”改成”用机器”
阿哲第 3 页那个”机柜自己从地里长出来”的画面,是弹性部署最核心的一件事。
它的逻辑很简单,就一句话:流量来了,秒级扩容顶上;流量走了,自动缩容退场。
平时你只挂着满足日常的那几台,成本压到最低。监控一旦发现流量往上冲,系统自动拉起一批新节点接住峰值——你不用半夜爬起来手动加机器。等峰过去了,多出来的节点自动熄灯收回,你不用记着去关。
漫画第 4 页那张 ¥328.60 的账单,就是这个意思——你只为实际用掉的那部分算力付费,按秒计费,精度到毫秒。
那 27 台只在高峰时存在了几个小时的机器,账单上就只有那几个小时。剩下 360 天,它们根本不在你的成本里,因为它们根本不属于你——它们来自共绩那张整合了全国 70 万台闲时设备的算力网,用的时候调过来,不用的时候还回去。
这就是”养机器”和”用机器”的根本区别。
养,是它归你,开着就计费;用,是你要结果,算完就释放。
🔍 但作为技术负责人,我会先盯着这几个问题
讲到这,如果你是个有经验的技术负责人,心里应该已经升起几个问号了。这才是该有的反应——弹性听起来很美,但魔鬼在细节里。我把你最该问的几个问题摆出来。
第一,扩容到底有多快?冷启动会不会拖后腿?
这是弹性部署最关键的硬指标。流量是秒级冲上来的,如果你的扩容要几分钟才能拉起一个可用节点,那峰值早就把你冲垮了,扩了也白扩。尤其是大尺寸镜像(带模型权重那种),冷启动慢是通病。这一项你接入前一定要实测——拿你自己的真实镜像,测一下从”触发扩容”到”新节点真正接客”要多久。共绩主打的是大尺寸镜像快速冷启动和多节点快速冷启动,但具体到你的业务,数据要自己跑一遍才算数。
第二,扩容/缩容的过程中,会不会丢请求?
这是比”快不快”更隐蔽的坑。扩容时新节点没就绪就被打流量、缩容时正在处理的请求被误杀——这些都会变成线上故障。健康检查、优雅下线这些机制到不到位,决定了弹性是”平滑过渡”还是”抖动事故”。这块要看平台有没有做好就绪探针和连接排空。
第三,底层是闲时算力,单点不稳,我的在线服务扛得住吗?
这是我个人最关心的一点。共绩的供给本质是闲时设备,单台随时可能掉线。它的解法是毫秒级切换——某个节点退出,瞬间切到备用节点,整体稳定性做到 99.99%。漫画里没画的那个 1963 台机器轮换、前台零波动的案例,就是在说这件事。但你得清楚:这个稳定性是”调度层兜出来的”,不是”单台机器靠谱”。 对绝大多数 Web 服务、推理服务,这个层级足够;但如果你的业务对单点延迟极度敏感(比如高频交易那种微秒级),那要谨慎评估。
第四,免运维,是真免还是话术?
漫画第 5 页阿哲睡到天亮,是这套东西最诱人的承诺。但说句实在话——没有任何系统能让你完全不操心。 弹性部署能帮你免掉的是”半夜手动加机器、手动关机器”这类机械运维。但扩缩容的策略阈值、健康检查的配置、容量上限的设定,这些判断还得你来做。它把你从”救火队员”变成”规则制定者”,但没把你变成甩手掌柜。这个预期摆正了,你才不会失望。
一句话:弹性部署不是让你不用管,是让你不用”半夜爬起来管”。
🚫 也得说清楚:这几种情况,别上弹性部署
不藏着掖着。弹性部署不是万能药,有几种场景它不划算,甚至不合适。
- 流量平稳、可预测的常驻服务:如果你的负载常年稳定,没什么波峰波谷,那弹性的价值就不大,直接包年包月租固定的反而更省心、单价可能更低。弹性的红利来自”波动”,没波动就没红利。
- 对冷启动零容忍的极低延迟服务:第一个请求必须毫秒级响应、不能有任何冷启动延迟的场景,弹性扩容的那一下可能会让你难受。
- 强状态、难迁移的服务:弹性的前提是节点可以随时拉起和销毁。如果你的服务带着大量本地状态、迁移起来很痛,那它跟”随时换机器”的弹性模型天然不合。
判断标准就一句话:你的成本痛点,是不是来自”为高峰常备容量”? 是,弹性部署就是对症的药;不是,就别硬上。
顺带说一句区分:如果你要跑的是离线的、可中断的批量任务(批量出图、转码、评测那种),那是 Job 批处理该干的活;弹性部署是给在线服务用的,扛的是实时流量。两者别搞混。
🌊 说到底,算力本该像呼吸一样起伏
漫画最后一页那条会”呼吸”的曲线,是我最喜欢的一格。
流量高的时候,机器多一点;流量低的时候,机器少一点。像呼吸,自然而然。
可现实里,我们大多数人是怎么过来的?
我们按最大吸气量,给自己造了一个永远鼓着的肺,然后为这口憋着的气,付了一整年的钱。
这不正常,只是我们习惯了。
技术负责人这个岗位,最大的进步可能不是学会了什么新技术,而是某一天突然意识到——有些我们以为”必须承受”的成本和焦虑,其实只是因为没有更好的工具。
阿哲那一晚没崩,第二天也没收到天价账单,半夜手机也没响。
不是因为他更拼了,是因为他不用再拼这件事了。
如果你也在为”养着一整年、只用几天”的服务器交学费,共绩算力的弹性部署值得你拿真实业务测一测——重点测那几个硬指标:冷启动速度、扩缩容的平滑度、还有那张只算实际用量的账单。
suanli.cn,弹性部署。流量来了秒扩,走了秒缩,只付用掉的。
你上一次为流量提心吊胆,是什么时候?
那一晚,你守的到底是业务,还是一屋子空转的机器?